
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |
- Iperf3
- golang uuid
- Golang디자인패턴
- 리플렉션성능
- 디자인패턴학습필요성
- Golang벤치마킹
- Golang부하테스트
- go리플렉션성능
- vue3
- Line차트
- Go디자인패턴
- go로드맵
- 디자인패컨
- Go벤치마크
- 챠트그리기
- Go성능테스트
- vue3-chartjs
- vue3 통신
- line챠트
- Vue.js
- 대역폭측정하기
- vue3 axios
- GObenchmark
- GO벤치마킹
- Golang성능테스트
- golang벤치마크
- pprof
- Golangbenchmark
- snoflake
- GO부하테스트
- Today
- Total
import ( "코딩", "행복", "즐거움" )
데이터베이스의 구조 이해 본문
원문 : https://zenn.dev/revenuehack/articles/dc5a901fbe90e6
データベースの仕組み(アーキテクチャ)をざっくり理解する
DDDやCleanなどの設計やAWSが好き→MENTAで教えています 基本専らGoを書いています。 AWS SAA保持者
zenn.dev
데이터베이스(RDB)의 구조(아키텍처)는 대체로 동일하다.
RDB라고 하면
Oracle
SQLServer
MySQL
Postgres
등이 유명하다고 할 수 있습니다.
다만 RDB의 세부적인 사양이나 디자인, 네이밍은 다르지만 기본적으로 모든 RDB는 비슷한 아키텍처를 가지고 있습니다.
따라서 하나의 RDB의 구조를 따라가면 대략적으로 이해할 수 있습니다.
이번에는 MySQL을 주제로 아키텍처를 설명해 보겠습니다!
SQL의 처리 흐름
먼저 아키텍처에 앞서 SQL의 흐름을 간단히 정리해 보겠습니다.
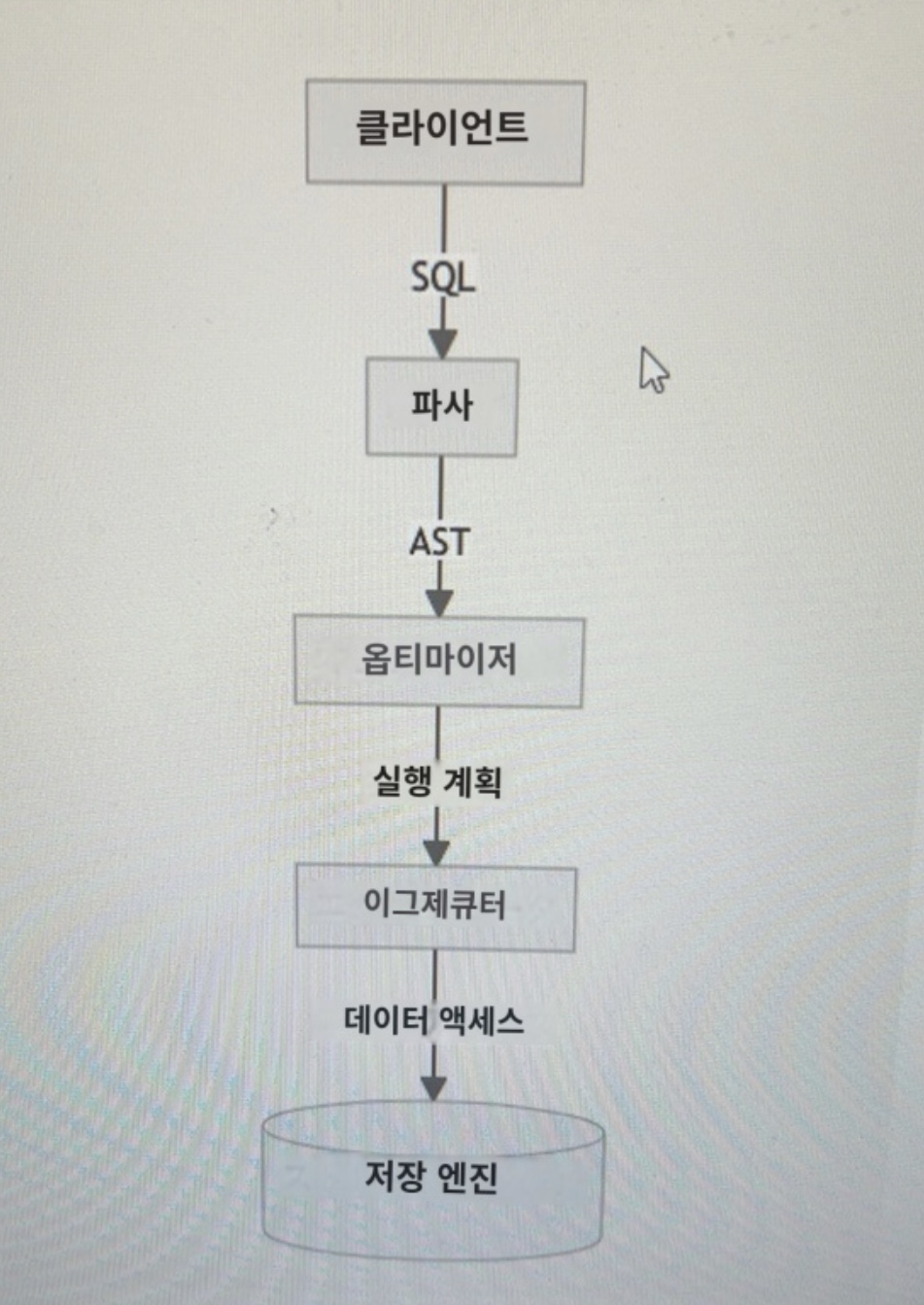
먼저 클라이언트에서 SQL을 입력하면 파서에서 SQL을 분석하여 AST(추상 구문 트리)를 생성한다.
생성된 추상 구문 트리에서 옵티마이저가 사전에 수집한 데이터를 바탕으로 여러 가지 실행 계획을 만들어 비용을 정량화한다.
그 중 비용이 가장 낮은 실행 계획을 실행하고, 실행자가 스토리지 엔진에 접속하여 SQL 결과를 도출한다.
라는 흐름으로 되어 있습니다.

분석 트리의 이미지는 다음과 같습니다.
옵티마이저 트레이스 예시
MySQL에서는 json으로 SQL의 옵티마이저 트레이스 결과를 출력할 수 있도록 되어 있습니다.
실제로 출력해 보면 다음과 같은 모습입니다.
5.7 이상에서는 비용도 제대로 표시되므로, SQL을 조사하고 싶은 분들에게 좋습니다!
EXPLAIN FORMAT=JSON SELECT ...
explain 시 FORMAT=JSON을 붙이면 OK입니다!
{
"query_block": {
"select_id": 1,
"cost_info": {
"query_cost": "404995.39"
},
"nested_loop": [
{
"table": {
"table_name": "l",
"access_type": "ALL",
"rows_examined_per_scan": 331143,
"rows_produced_per_join": 331143,
"filtered": "100.00",
"cost_info": {
"read_cost": "4141.79",
"eval_cost": "33114.30",
"prefix_cost": "37256.09",
"data_read_per_join": "5M"
},
"used_columns": [
"emp_no",
"from_date",
"to_date"
],
"materialized_from_subquery": {
"using_temporary_table": true,
"dependent": false,
"cacheable": true,
"query_block": {
"select_id": 3,
"cost_info": {
"query_cost": "33851.30"
},
"grouping_operation": {
"using_filesort": false,
"table": {
"table_name": "dept_emp",
"access_type": "index",
"possible_keys": [
"PRIMARY",
"dept_no"
],
"key": "PRIMARY",
"used_key_parts": [
"emp_no",
"dept_no"
],
"key_length": "20",
"rows_examined_per_scan": 331143,
"rows_produced_per_join": 331143,
"filtered": "100.00",
"cost_info": {
"read_cost": "737.00",
"eval_cost": "33114.30",
"prefix_cost": "33851.30",
"data_read_per_join": "10M"
},
"used_columns": [
"emp_no",
"dept_no",
"from_date",
"to_date"
]
}
}
}
}
}
},
{
"table": {
"table_name": "d",
"access_type": "ref",
"possible_keys": [
"PRIMARY"
],
"key": "PRIMARY",
"used_key_parts": [
"emp_no"
],
"key_length": "4",
"ref": [
"employees.l.emp_no"
],
"rows_examined_per_scan": 1,
"rows_produced_per_join": 16557,
"filtered": "4.52",
"cost_info": {
"read_cost": "331143.00",
"eval_cost": "1655.72",
"prefix_cost": "404995.39",
"data_read_per_join": "517K"
},
"used_columns": [
"emp_no",
"from_date",
"to_date"
],
"attached_condition": "((`employees`.`d`.`to_date` = `employees`.`l`.`to_date`) and (`employees`.`d`.`from_date` = `employees`.`l`.`from_date`))"
}
}
]
}
} |선정된 실행계획을 설명하면 다음과 같습니다
+----+-------------+------------+------------+-------+-----------------+---------+---------+--------------------+--------+----------+-------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+------------+------------+-------+-----------------+---------+---------+--------------------+--------+----------+-------------+
| 1 | PRIMARY | <derived3> | NULL | ALL | NULL | NULL | NULL | NULL | 331143 | 100.00 | NULL |
| 1 | PRIMARY | d | NULL | ref | PRIMARY | PRIMARY | 4 | employees.l.emp_no | 1 | 4.52 | Using where |
| 3 | DERIVED | dept_emp | NULL | index | PRIMARY,dept_no | PRIMARY | 20 | NULL | 331143 | 100.00 | NULL |
+----+-------------+------------+------------+-------+-----------------+---------+---------+--------------------+--------+----------+-------------+
데이터베이스(RDB)의 구조(아키텍쳐)에 대하여
이제 어느 정도 SQL의 처리 구조와 흐름을 알았다면, 이제 본론인 데이터베이스의 아키텍처에 대해 알아보도록 하겠습니다!
미리 말씀드리자면, 어디까지나 정석적인 흐름을 소개하기 때문에, 이번과는 다른 엣지 케이스의 처리 흐름을 따라갈 수도 있습니다!

| 이름 | 설명 | 영역 |
| Buffer pool | 데이터의 캐시가 위치하는 영역. 기본적으로 이 영역에 테이블이나 인덱스 데이터가 놓여지고, 이곳을 통해 데이터가 반환된다. 일반적으로 메모리의 50~80% 정도를 이 영역에 사용 | In Memory |
| Log Buffer | 디스크의 로그 파일에 기록되는 데이터를 일시적으로 보관하는 영역으로, redo 로그에 데이터를 플러시하기 전에 트랜잭션이 커밋될 때까지 개별 영역으로 보관한다. | In Memory |
| Redo Log | INSERT 시 등 COMMIT 타이밍에 데이터가 기록되는 영역. 크래시 복구 시 대응할 수 있도록 비휘발성 스토리지에 쓰도록 되어 있다 | 스토리지 |
| Tablesspaces | 테이블이나 인덱스의 데이터가 있는 영역 | 스토리지 |
| Undo Log | 그림에는 적혀있지 않지만, 트랜잭션 롤백 등 최신 변경사항을 되돌릴 때 데이터가 저장되는 영역 | 저장소 |
데이터베이스의 스토리지 엔진의 처리 흐름은 이런 식으로 되어 있고, 이름은 RDB마다 다르지만, 아키텍처의 구조는 기본적으로 모든 RDB가 동일합니다.
따라서 데이터베이스에 문제가 생겼을 때, 위의 그림을 떠올리면 도움이 될 것입니다!
SELECT의 처리 흐름
이제 실제로 SELECT의 SQL이 발행되었을 때의 처리 흐름을 설명하겠습니다.
우선 데이터는 기본적으로 인메모리의 Buffer pool에서 데이터를 가져오는 구조로 되어 있습니다.
Buffer pool에 SELECT하고자 하는 데이터가 없는 경우, Tablespaces에서 데이터를 가져와서 가져옵니다.
이때는 디스크를 불러오기 때문에 I/O 부하가 발생하게 됩니다.
한번 가져온 데이터는 Buffer pool의 용량이 허락하는 한 캐시됩니다. 따라서 예를 들어 SELECT * from users where id = 1이라는 쿼리를 한 번 실행한 경우, 다음에는 Buffer pool에 데이터가 있기 때문에 I/O 부하가 발생하지 않습니다.
Buffer pool은 LRU 알고리즘으로 데이터 취사선택을 하고 있습니다. 대략적으로 말하자면, 읽기 빈도가 높은 페이지는 남기고 사용 빈도가 낮은 페이지를 삭제하는 알고리즘으로, 그렇게 함으로써 효율적으로 캐시를 운용하고 있습니다(단, 엄밀히 말하면 MySQL에서는 LRU 알고리즘이 아닌 것 같습니다 ※참고문헌).
어디까지나 정통적인 흐름에 대한 설명이므로, 당시의 CPU나 메모리, 각 영역의 상태에 따라 위와 같은 흐름에서 벗어나는 엣지 케이스도 있을 수 있습니다.
INSERT 등의 처리 흐름
INESERT INTO users VALUES (1, 'hoge')와 같은 SQL을 실행하는 경우를 가정해 보자.
먼저 기본적으로 Buffer pool에 데이터가 다시 쓰여집니다
(갑자기 Tablespaces의 저장소에 쓰여지지 않는다는 점에 주의해야 합니다).
이어서 그대로 Log buffer에 INSERT한 데이터를 기록합니다(여기까지는 인메모리이기 때문에 빠릅니다).
COMMIT이 호출된 타이밍에 Log buffer에 있는 INSERT한 데이터를 Read Log에 쓰기 위해 이동합니다
(여기서 처음으로 비휘발성 스토리지에 쓰여져 영구화됩니다).
마지막으로 체크포인트라는 정해진 발생 타이밍에 INSERT된 데이터가 Tablespaces에 쓰여지는 흐름이 됩니다
(체크포인트의 타이밍은 다양하며, redo 로그 파일 크기만큼의 데이터 블록이 쓰여졌을 때, 지정된 시간 간격, CPU 부하가 적을 때 등 다양하다.)
데이터베이스(RDB)의 구조를 이해하면 인덱스를 붙이는 요령을 알 수 있다.
지금까지 데이터베이스(RDB)의 아키텍처 구조에 대해 간략하게 설명드렸습니다.
제품에서 성능의 병목현상이 발생하는 것은 대부분 데이터베이스입니다.
데이터베이스의 아키텍처와 구조, 인덱스를 효율적으로 붙이는 방법을 알아두면 웹 엔지니어로서 커리어를 쌓는 데에도 도움이 되니 잘 알아두면 좋을 것 같습니다!

'잡다한 테크지식' 카테고리의 다른 글
| 마이크로서비스 아키텍처 ( microservice ) (0) | 2022.10.03 |
|---|